Используемый язык формирует контекст работы LLM и выступает «системным промптом» – что влияет и на общую эффективность работы с моделью, рассказал inTrend руководитель Лаборатории искусственного интеллекта Школы управления СКОЛКОВО Александр Диденко.
Влияние контекста на ответы LLM Лаборатория искусственного интеллекта оценила в своем первом исследовании – с ценными выводами для бизнеса, особенно работающего с клиентами с различными культурными бэкграундами.
Компании, понимающие необходимость адаптации LLM-решений к культурным нормам на различных рынках, могут получить конкурентное преимущество. В перспективе речь о «пироге» в сотни миллиардов долларов.
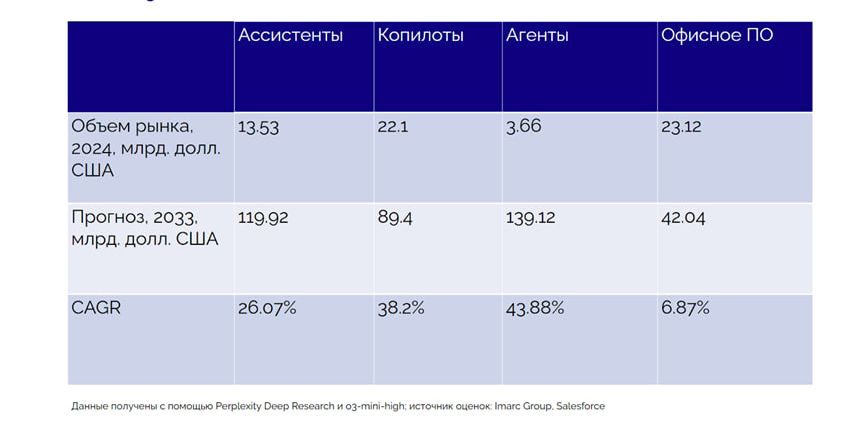
Согласно расчетам, приведенным в исследовании Лаборатории искусственного интеллекта, глобальный спрос на ИИ-ассистентов, ИИ-копилотов и ИИ-агентов (отличаются друг от друга по степени автономности и функционалу) к 2033 году может вырасти почти до $350 млрд – против $38 млрд на 2024 год. Рост почти на порядок.
То, что язык запроса влияет на характер ответа LLM, уже понятно – но почему так происходит?
Александр Диденко: Действительно, когда мы задавали вопросы на итальянском, модели чаще давали более позитивные ответы. Даже когда речь шла о простом числовом ответе по шкале, модели склонялись выбирать более высокие значения, которые ассоциируются с позитивом.
А вот на немецком ответы были гораздо более сдержанными. Русский и английский, кстати, оказались где-то посередине, так что Россия – не «страна для грустных». Скорее, Германия, исходя из этого эксперимента (смеется).
Почему так происходит?
Мы пришли к выводу, что сам язык уже является контекстом. Он как бы становится для модели своеобразным «системным промптом», даже если мы явно этого не задаем. То есть, формулируя вопрос на определенном языке, мы запускаем в модели не только лингвистический, но и культурный контекст
«В Риме веди себя, как римлянин» – модель принимает правила игры и «вживается» в роль носителя того или иного культурного кода. Возможно, все это связано с тем, на каких данных обучалась модель, и какие ассоциации и паттерны были в этих данных заложены.
А что сильнее влияет на ответ – язык, на котором сформулирован вопрос, или культурные особенности самой модели, связанные с культурными особенностями ее разработчиков?
Александр Диденко: Влияние языка сильнее. Независимо от того, какая именно модель использовалась, язык определял характер ответа.
Это важный вывод, особенно для тех, кто разрабатывает чат-ботов или сервисы, работающие на нескольких языках. Потому что даже если вы думаете, что задали универсальный контекст, язык может внести свои коррективы, и модель начнет отвечать по-своему.
Поэтому тестировать такие системы нужно обязательно на каждом языке отдельно, чтобы убедиться, что тональность, стиль и содержание ответов соответствуют ожиданиям. Иначе можно получить неожиданный результат — когда на одном языке модель вежлива и позитивна, а на другом — сдержанна и даже холодна.
Иными словами, когда мы работаем с многоязычными системами, мы сталкиваемся не просто с задачей перевода, а с задачей культурной адаптации. И без учета этого нюанса можно получить результаты, которые будут далеки от ожидаемых, как по содержанию, так и по тону.
А есть ли корреляция между культурными особенностями страны, где создается та или иная LLM, и культурными особенностями самой модели? Условно, транслируют ли российские модели некие «российские культурные ценности»?
Александр Диденко: Тут интересно. Когда мы анализировали культурные профили разных моделей, результаты оказались довольно неожиданными.
Например, российские модели — «Яндекс GPT» и GigaChat (разработка «Сбера») — по своему культурному коду больше напоминали скандинавские страны, такие как Швеция или Дания, чем Россию. Они демонстрировали высокий индивидуализм, низкую иерархичность, склонность к принятию риска и долгосрочную ориентацию.
А вот китайские модели, наоборот, по своим характеристикам были ближе к Нидерландам, что, согласитесь, довольно парадоксально.
Мы изначально ожидали, что культурный код моделей будет ближе к культуре страны, в которой они были разработаны. Но на практике оказалось иначе. Например, российские модели показали наименьшую дистанцию к власти.
Это значит, что они как будто бы «предпочитают» плоские, неиерархичные структуры общения. При этом они демонстрируют высокую склонность к индивидуализму и долгосрочному планированию. Это совсем не похоже на традиционные российские культурные установки, которые обычно считаются более коллективистскими и иерархичными.
Почему так произошло? У нас есть несколько гипотез.
Во-первых, возможно, это связано с мировоззрением и ценностями тех, кто непосредственно участвовал в разработке и разметке данных для этих моделей.
В крупных технологических компаниях, особенно в больших городах, часто преобладают более индивидуалистические взгляды. И эти установки, возможно, невольно отражаются в процессе обучения модели.
Во-вторых, важно учитывать, что сами датасеты, на которых обучаются модели, могут быть «размытыми» и содержать информацию, не всегда точно отражающую локальный культурный контекст.
Кроме того, модели учатся на огромных объемах текстов, и в них могут доминировать определенные паттерны, которые не всегда совпадают с реальными социальными установками той или иной страны.
Еще одна гипотеза — что модели могли унаследовать «глобальный» культурный код, который формируется в международном цифровом пространстве. Он может быть ближе к западным установкам, где больше ценится индивидуализм, ориентация на личный успех и свобода самовыражения.
Эти результаты для нас стали поводом задуматься: если модели отражают не столько локальную культуру, сколько культуру определенных сообществ, то, возможно, для более точной локализации потребуется более тщательная работа с разметкой и тестированием. И это еще одно направление, в котором предстоит много работы.
Хорошо, но в таком случае как минимизировать «культурные предубеждения» моделей?
Александр Диденко: Критически важно учитывать разнообразие разметчиков. Дело в том, что культурный код модели во многом формируется не только за счет данных, на которых она обучается, но и через процесс разметки, когда люди взаимодействуют с моделью, оценивают ее ответы и корректируют их.
И вот тут возникает главный вопрос — кто эти люди? Если основная часть разметчиков принадлежит к одной культурной группе, модели, скорее всего, унаследуют именно этот культурный взгляд.
Например, если в процессе обучения доминируют специалисты из больших городов с определенным мировоззрением, именно их установки и предпочтения могут стать «нормой» для модели.
И это как раз объясняет, почему наши российские модели оказались ближе к скандинавским культурам, с их ориентацией на индивидуализм и плоские иерархии. Вероятно, этот профиль отразил установки тех, кто непосредственно работал с моделью на стадии ее финального обучения.
Чтобы минимизировать этот эффект, есть два возможных пути.
Первый — формировать максимально разнообразные команды разметчиков. Если мы хотим, чтобы модель отражала более широкий культурный спектр, логично привлекать людей из разных социальных и культурных контекстов. Например, из разных регионов, возрастных групп, с разным профессиональным опытом. Это позволит сбалансировать возможные перекосы и сделать модель более универсальной.
Второй путь — дать разметчикам четкие инструкции, ориентированные на определенный культурный код. Но, как показали наши исследования, даже с системными промптами повлиять на культуру модели крайне сложно. Поэтому первый путь — через диверсификацию — выглядит более надежным.
Еще одна важная мысль: необходимо тестировать модели на соответствие разным культурным ожиданиям. Даже если у вас есть ощущение, что модель обучена нейтрально, тестирование может показать неожиданные перекосы. Например, когда модель уверенно выбирает одну стратегию убеждения и игнорирует другую, хотя с точки зрения культурного контекста это неочевидно.
В итоге мы пришли к выводу, что процесс обучения и разметки — это не только техническая задача, но и глубокая работа с культурным разнообразием. Если игнорировать этот фактор, велик риск создать модель, которая будет работать корректно только для узкой аудитории, а для остальных — выдавать неуместные или даже ошибочные ответы. Прямо как с воспитанием детей.
